
As a head-up to the SEMANTiCS 2016 we invited several experts from the joint project Linked Enterprise Data Service (LEDS) to talk a bit about their work and visions. They will share their insights into the fields of natural language processing, e-commerce, e-government, data integration and quality assurance right here. So stay tuned.
As CEO of the Ontos GmbH and a media informatics scientist with a PhD in the interface between web engineering, semantic web and information visualization, Martin Voigt knows how painstaking the study of entire documents is. That’s his genuine motivation to develop natural language processing technologies (NLP) which allows to skip the document stacks and go right to the really relevant information therein. His vision is simple as it is challenging: to give a comprehensible overview of a document with a sufficient depth of detail. Therefore, with his Ontos GmbH he relentlessly works within the stress field of semantic web technologies and deep learning methodologies, and is up to his ears in a multitude of German and European scientific projects.
So it doesn’t come as a surprise that Martin manages the work packet ASP-C of LEDS, tackling the challenges of information extraction. If Martin could use NLP technologies all by himself, he’d love to explore the relation of medical side effects of multiple medicines as well as the connection between law texts and the lobbyist influence of large corporations. To be honest, we’d like to know the outcome as well. So please, Martin, tell us when you got the results.
As a fun fact we should add that Martin met his future employer from Ontos, Daniel Hladky, at a SEMANTiCS conference. Two years later he took the position of the CEO. So SEMANTiCS is always worth a visit.
What’s the status quo in the development of the Natural Language Processing?
Martin: On the one hand, Natural Language Processing (NLP) has already been subject of research and development for a long time. On the other hand, it’s also a very broad topic too. The „Survey of the State of the Art in Human Language Technology“ by Cole et al. gives you a quite good idea of just how huge this research field is.
In a nutshell, NLP is about the question, how a "computer" can process and understand the natural human language, for example German, English or Japanese, for any purpose. Very often NLP is synonymous with Computational Linguistics (CL). This is more or less the same subject, though fellows in the field of NLP are more practically oriented. Current research areas include the written and spoken speech input and output, various forms of information extraction as well as the evaluation of systems. Of course, the years of research have already arrived in daily use, now more than ever.Just think about:
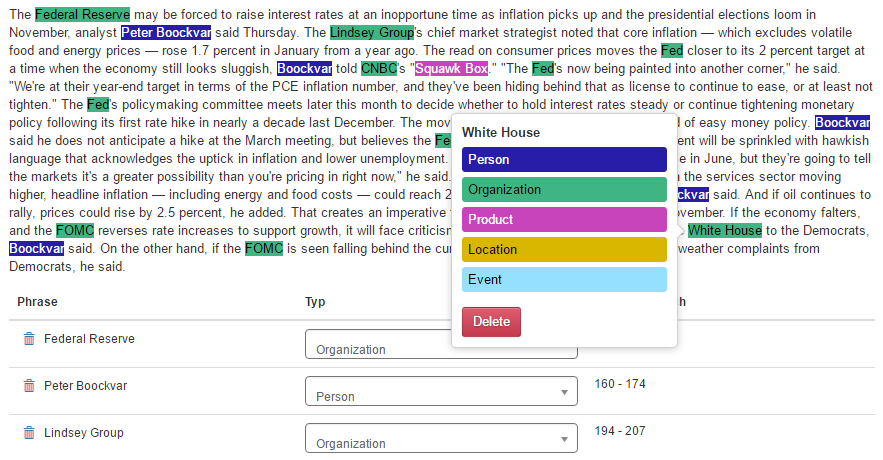
Annotation of different types of named entities in MINER (e.g. person, product or location)
What is your forecast for NLP in five to ten years?
Advanced machine learning, new semantic technologies as well as better and much cheaper hardware will transform and support our everyday life tasks. I think about:
What are the challenges to achieve that?
Due to the extent of the research field of NLP it’s difficult to name technological details which need to be solved. This would go beyond the scope of this post. However, to give an idea I want to give an outline of some challenges regarding information extraction with the next question.
But apart from technological details, it’s crucial that the different domains like Computational Linguistics and Natural Language Processing, Semantic Web, Machine Learning and Human Computer Interaction a brought to a closer cooperation. Whilst there are already some multi-disciplinary research projects, many of the research groups still do their own thing.
How does the LEDS project address these challenges?
Replacement of rule-based NLP systems by deep learning
LEDS’ - and Ontos’ - main objective is an improved, efficient transferability of the NLP approach for extracting information across different domains and languages - but without having to laboriously define and adapt thousands, partly fixed rules. That’s why we transfer the new possibilities of machine learning, especially deep learning (DL) as used in solutions of software companies such as Google, Facebook or Microsoft to the problem area. The advantages are clear:
Fact-based information extraction
Today’s tools focus on the extraction of particular entities of different concepts. For example, take the following sentence: "Adam Neumann is the CEO of super-hot office rental company WeWork, the most valuable startup in New York City."
It is state of the art of rule-based NLP to extract the entities "Adam Neumann" (person), "WeWork" (organization) or "New York City" (City) from the set.
DL technology will allow to efficiently extract new concepts as "CEO" (position) or "super-hot" (positive sentiment). However, the major goal of LEDS and Ontos goes even further: the extraction of factual knowledge, hence relations between the entities, as well as the generation of a semantic network from the collected information. From that example alone, many semantic facts can be obtained:
So you can imagine what you can extract from a text message with about 3000 words in average. To extract this information and utilize it in e.g. intelligent search engines is an essential goal of LEDS.
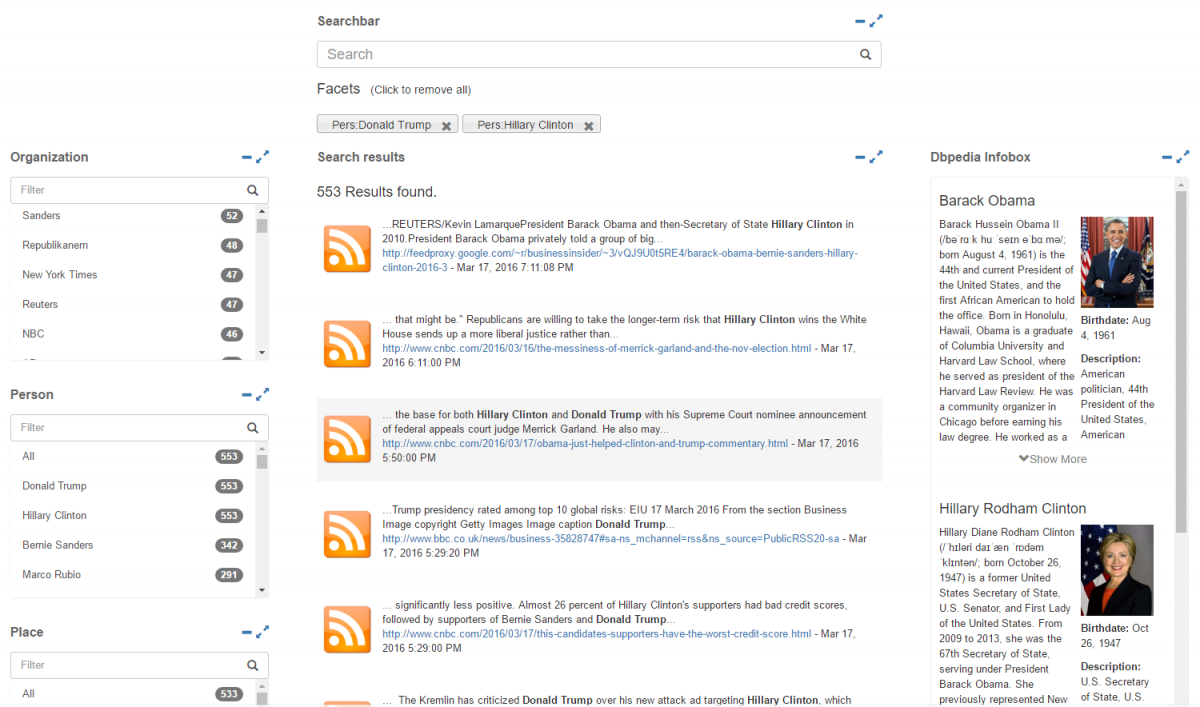
Application of found entities for search cases as well as for the display of further information from the knowledge engine DBpedia
Disambiguation of entities
A third project goal in terms of NLP is the development of concepts and prototypes to derive the unambiguous meaning of found entities. A simple example is the different spelling of the German Chancellor in different languages: Angela Merkel (German), Ангела Меркель (Russian) and Άνγκελα Μέρκελ (Greek). Another example are abbreviations such as "DB" which - depending on the context - must be clearly mapped to "German Railway" or "German Bank", respectively. To achieve this, we use a technology mix of DL on the one hand and semantic technologies as well as Linked Open Data Cloud on the other hand. In particular the last-mentioned approaches are utilized in the project to extract information from structured (database) and semi-structured data sources (among others social networks) and to combine them in a meaningful way.
LEDS is a joint research project addressing the evolution of classic enterprise IT infrastructure to semantically linked data services. The research partners are the Leipzig University and Technical University Chemnitz as well as the semantic technology providers Netresearch, Ontos, brox IT-Solutions, Lecos and eccenca.
|
brox IT-Solutions GmbH |
Leipzig University |
Ontos GmbH |
TU Chemnitz |
Netresearch GmbH & Co. KG |
Lecos GmbH |
eccenca GmbH |
 |
|